Method
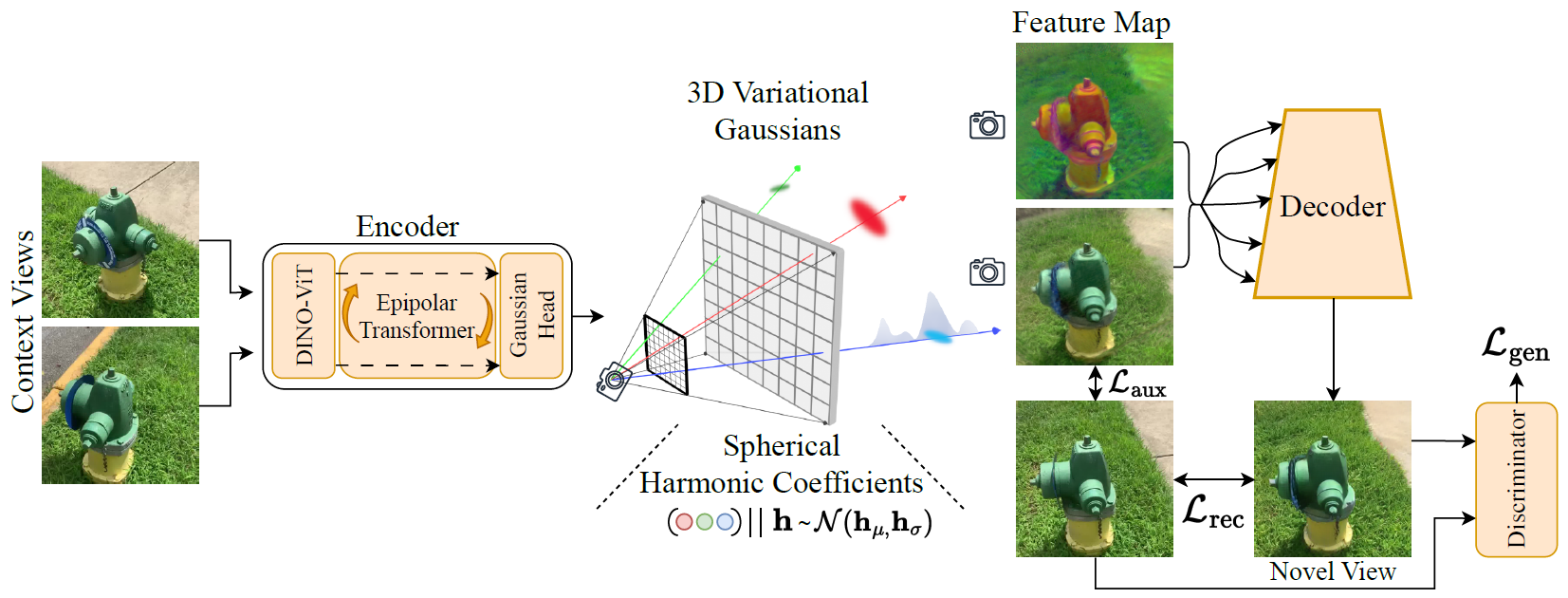
We present latentSplat, a method for scalable generalizable 3D reconstruction from two views. The architecture follows an autoencoder structure. (Left) Two input reference views are encoded into a 3D variational Gaussian representation using an epipolar transformer and a Gaussian sampling head. (Center) Variational Gaussians allow sampling of spherical harmonics feature coefficients that determine a specific instance of semantic Gaussians. (Right) The sampled instance can be rendered efficiently via Gaussian splatting and a light-weight VAE-GAN decoder.